蒙特卡罗模拟
此词条暂由彩云小译翻译,翻译字数共4901,未经人工整理和审校,带来阅读不便,请见谅。
Monte Carlo methods, or Monte Carlo experiments, are a broad class of computational algorithms that rely on repeated random sampling to obtain numerical results. The underlying concept is to use randomness to solve problems that might be deterministic in principle. They are often used in physical and mathematical problems and are most useful when it is difficult or impossible to use other approaches. Monte Carlo methods are mainly used in three problem classes:[1] optimization, numerical integration, and generating draws from a probability distribution.
Monte Carlo methods, or Monte Carlo experiments, are a broad class of computational algorithms that rely on repeated random sampling to obtain numerical results. The underlying concept is to use randomness to solve problems that might be deterministic in principle. They are often used in physical and mathematical problems and are most useful when it is difficult or impossible to use other approaches. Monte Carlo methods are mainly used in three problem classes: optimization, numerical integration, and generating draws from a probability distribution.
蒙特卡罗方法 Monte Carlo methods,或称蒙特卡罗实验 Monte Carlo experiments,是一大类计算算法的集合,它们依赖于重复的随机抽样来获得数值结果。其基本概念是利用随机性来解决原则上可能是确定性的问题。它们通常用于物理和数学问题,当问题很棘手或无法使用其他方法时,往往它们最有用。蒙特卡罗方法主要用于3个问题类: 优化,数值积分,依据概率分布生成图像。
In physics-related problems, Monte Carlo methods are useful for simulating systems with many coupled degrees of freedom, such as fluids, disordered materials, strongly coupled solids, and cellular structures (see cellular Potts model, interacting particle systems, McKean–Vlasov processes, kinetic models of gases).
In physics-related problems, Monte Carlo methods are useful for simulating systems with many coupled degrees of freedom, such as fluids, disordered materials, strongly coupled solids, and cellular structures (see cellular Potts model, interacting particle systems, McKean–Vlasov processes, kinetic models of gases).
在物理相关的问题中,蒙特卡罗方法可用于模拟具有多个耦合自由度的系统,如流体、无序材料、强耦合固体和细胞结构(参见细胞波茨模型、相互作用粒子系统、 麦肯-弗拉索夫 McKean-Vlasov 过程、气体动力学模型)。
Other examples include modeling phenomena with significant uncertainty in inputs such as the calculation of risk in business and, in mathematics, evaluation of multidimensional definite integrals with complicated boundary conditions. In application to systems engineering problems (space, oil exploration, aircraft design, etc.), Monte Carlo–based predictions of failure, cost overruns and schedule overruns are routinely better than human intuition or alternative "soft" methods.[2]
Other examples include modeling phenomena with significant uncertainty in inputs such as the calculation of risk in business and, in mathematics, evaluation of multidimensional definite integrals with complicated boundary conditions. In application to systems engineering problems (space, oil exploration, aircraft design, etc.), Monte Carlo–based predictions of failure, cost overruns and schedule overruns are routinely better than human intuition or alternative "soft" methods.
其他例子包括对输入中具有重大不确定性的现象进行建模,如商业中的风险计算,以及在数学中对具有复杂边界条件的多维定积分进行评估。 在系统工程问题(空间、石油勘探、飞机设计等)的应用中,基于蒙特卡罗的故障预测、成本超支和进度超支通常比人类的直觉或其他的“软性”方法更好。
In principle, Monte Carlo methods can be used to solve any problem having a probabilistic interpretation. By the law of large numbers, integrals described by the expected value of some random variable can be approximated by taking the empirical mean (a.k.a. the sample mean) of independent samples of the variable. When the probability distribution of the variable is parametrized, mathematicians often use a Markov chain Monte Carlo (MCMC) sampler.[3][4][5] The central idea is to design a judicious Markov chain model with a prescribed stationary probability distribution. That is, in the limit, the samples being generated by the MCMC method will be samples from the desired (target) distribution.[6][7] By the ergodic theorem, the stationary distribution is approximated by the empirical measures of the random states of the MCMC sampler.
In principle, Monte Carlo methods can be used to solve any problem having a probabilistic interpretation. By the law of large numbers, integrals described by the expected value of some random variable can be approximated by taking the empirical mean (a.k.a. the sample mean) of independent samples of the variable. When the probability distribution of the variable is parametrized, mathematicians often use a Markov chain Monte Carlo (MCMC) sampler. The central idea is to design a judicious Markov chain model with a prescribed stationary probability distribution. That is, in the limit, the samples being generated by the MCMC method will be samples from the desired (target) distribution. By the ergodic theorem, the stationary distribution is approximated by the empirical measures of the random states of the MCMC sampler.
理论上,蒙特卡罗方法可以用来解决任何具有概率解释的问题。 根据大数定律,用某个随机变量的期望值描述的积分可以用该变量独立样本的经验均值(即样本均值)来近似。 当变量的概率分布被参数化时,数学家们经常使用马尔可夫链蒙特卡罗(MCMC)采样器。 中心思想是设计一个具有给定平稳概率分布的有效马尔可夫链模型。 也就是说,在极限情况下,MCMC方法生成的样本将成为来自期望(目标)分布的样本。 通过遍历定理,平稳分布可以用MCMC采样器随机状态的经验测度来近似。
In other problems, the objective is generating draws from a sequence of probability distributions satisfying a nonlinear evolution equation. These flows of probability distributions can always be interpreted as the distributions of the random states of a Markov process whose transition probabilities depend on the distributions of the current random states (see McKean–Vlasov processes, nonlinear filtering equation).[8][9] In other instances we are given a flow of probability distributions with an increasing level of sampling complexity (path spaces models with an increasing time horizon, Boltzmann–Gibbs measures associated with decreasing temperature parameters, and many others). These models can also be seen as the evolution of the law of the random states of a nonlinear Markov chain.[9][10] A natural way to simulate these sophisticated nonlinear Markov processes is to sample multiple copies of the process, replacing in the evolution equation the unknown distributions of the random states by the sampled empirical measures. In contrast with traditional Monte Carlo and MCMC methodologies these mean field particle techniques rely on sequential interacting samples. The terminology mean field reflects the fact that each of the samples (a.k.a. particles, individuals, walkers, agents, creatures, or phenotypes) interacts with the empirical measures of the process. When the size of the system tends to infinity, these random empirical measures converge to the deterministic distribution of the random states of the nonlinear Markov chain, so that the statistical interaction between particles vanishes.
In other problems, the objective is generating draws from a sequence of probability distributions satisfying a nonlinear evolution equation. These flows of probability distributions can always be interpreted as the distributions of the random states of a Markov process whose transition probabilities depend on the distributions of the current random states (see McKean–Vlasov processes, nonlinear filtering equation). In other instances we are given a flow of probability distributions with an increasing level of sampling complexity (path spaces models with an increasing time horizon, Boltzmann–Gibbs measures associated with decreasing temperature parameters, and many others). These models can also be seen as the evolution of the law of the random states of a nonlinear Markov chain. A natural way to simulate these sophisticated nonlinear Markov processes is to sample multiple copies of the process, replacing in the evolution equation the unknown distributions of the random states by the sampled empirical measures. In contrast with traditional Monte Carlo and MCMC methodologies these mean field particle techniques rely on sequential interacting samples. The terminology mean field reflects the fact that each of the samples (a.k.a. particles, individuals, walkers, agents, creatures, or phenotypes) interacts with the empirical measures of the process. When the size of the system tends to infinity, these random empirical measures converge to the deterministic distribution of the random states of the nonlinear Markov chain, so that the statistical interaction between particles vanishes.
在其他问题中,目标是从满足非线性发展方程的概率分布序列生成图。这些概率分布流总是可以解释为马尔可夫过程的随机状态的分布,其转移概率依赖于当前随机状态的分布(见麦肯-弗拉索夫 McKean-Vlasov过程,非线性滤波方程)。在其他情况下,我们给出了采样复杂度不断增加的概率分布流(如时间范围不断增加的路径空间模型,与温度参数降低有联系的玻尔兹曼—吉布斯 Boltzmann-Gibbs测度,以及许多其他例子)。这些模型也可以看作是一个非线性马尔可夫链的随机状态规律的演化。模拟这些复杂非线性马尔可夫过程的一个自然的方法是对过程的多个副本进行抽样,用抽样的经验测度替代演化方程中未知的随机状态分布。与传统的蒙特卡罗和 MCMC 方法相比,这些平均场粒子技术依赖于连续的相互作用样本。平均场一词反映了每个样本(也就是粒子、个体、步行者、媒介、生物或表现型)与过程的经验测量相互作用的事实。当系统的大小趋近于无穷时,这些随机经验测度收敛于非线性马尔可夫链随机状态的确定性分布,从而使粒子之间的统计相互作用消失。
Overview 概述
Monte Carlo methods vary, but tend to follow a particular pattern:
蒙特卡罗方法各不相同,但趋向于遵循一个特定的模式:
- Define a domain of possible inputs
Define a domain of possible inputs
1、定义可能输入的域
- Generate inputs randomly from a probability distribution over the domain
Generate inputs randomly from a probability distribution over the domain
2、从域上的概率分布随机生成输入
- Perform a deterministic computation on the inputs
Perform a deterministic computation on the inputs
3、对输入进行确定性计算
- Aggregate the results
Aggregate the results
4、汇总结果

Monte Carlo method applied to approximating the value of .
蒙特卡罗方法应用于估计。
For example, consider a quadrant (circular sector) inscribed in a unit square. Given that the ratio of their areas is 模板:Sfrac, the value of [[pi|模板:Pi]] can be approximated using a Monte Carlo method:模板:Sfn
For example, consider a quadrant (circular sector) inscribed in a unit square. Given that the ratio of their areas is |4}}, the value of pi| can be approximated using a Monte Carlo method:
例如,考虑一个单位正方形内嵌的四分之一圆。考虑到它们的面积比是π/4,π的值可以用蒙特卡罗方法来近似:
- Draw a square, then inscribe a quadrant within it
Draw a square, then inscribe a quadrant within it
1、画一个正方形,然后在其中划出一个四分之一圆
- Uniformly scatter a given number of points over the square
Uniformly scatter a given number of points over the square
2、在正方形上均匀散布给定数量的点
- Count the number of points inside the quadrant, i.e. having a distance from the origin of less than 1
Count the number of points inside the quadrant, i.e. having a distance from the origin of less than 1
3、计算四分之一圆内的点数,即满足距离原点小于1的
- The ratio of the inside-count and the total-sample-count is an estimate of the ratio of the two areas, 模板:Sfrac. Multiply the result by 4 to estimate 模板:Pi.
The ratio of the inside-count and the total-sample-count is an estimate of the ratio of the two areas, |4}}. Multiply the result by 4 to estimate .
四分之一圆内部计数与总样本计数之比是两个区域之比的估计值,π/4。把结果乘以4就可以估算出π的值。
In this procedure the domain of inputs is the square that circumscribes the quadrant. We generate random inputs by scattering grains over the square then perform a computation on each input (test whether it falls within the quadrant). Aggregating the results yields our final result, the approximation of 模板:Pi.
In this procedure the domain of inputs is the square that circumscribes the quadrant. We generate random inputs by scattering grains over the square then perform a computation on each input (test whether it falls within the quadrant). Aggregating the results yields our final result, the approximation of .
在这个过程中,输入域是限定四分之一圆的正方形。我们通过将颗粒散射到正方形上来产生随机输入,然后对每个输入执行计算(测试它是否在四分之一圆内)。汇总这些结果会产生最终的结果—π的近似值。
There are two important considerations:
有两个重要的考虑因素:
- If the points are not uniformly distributed, then the approximation will be poor.
If the points are not uniformly distributed, then the approximation will be poor.
1、如果这些点不是均匀分布的,那么近似效果就会很差。
- There are many points. The approximation is generally poor if only a few points are randomly placed in the whole square. On average, the approximation improves as more points are placed.
There are many points. The approximation is generally poor if only a few points are randomly placed in the whole square. On average, the approximation improves as more points are placed.
2、这一过程需要很多点。如果整个正方形中只有几个点是随机放置的,那么这个近似值通常是很差的。平均而言,随着放置更多的点,近似值精度会提升。
Uses of Monte Carlo methods require large amounts of random numbers, and it was their use that spurred the development of pseudorandom number generators[citation needed], which were far quicker to use than the tables of random numbers that had been previously used for statistical sampling.
Uses of Monte Carlo methods require large amounts of random numbers, and it was their use that spurred the development of pseudorandom number generators, which were far quicker to use than the tables of random numbers that had been previously used for statistical sampling.
应用蒙特卡罗方法需要大量的随机数,这也就刺激了伪随机数生成器的发展,伪随机数生成器的使用比以前用于统计抽样的随机数表要快得多。
History 历史
Before the Monte Carlo method was developed, simulations tested a previously understood deterministic problem, and statistical sampling was used to estimate uncertainties in the simulations. Monte Carlo simulations invert this approach, solving deterministic problems using probabilistic metaheuristics (see simulated annealing).
Before the Monte Carlo method was developed, simulations tested a previously understood deterministic problem, and statistical sampling was used to estimate uncertainties in the simulations. Monte Carlo simulations invert this approach, solving deterministic problems using probabilistic metaheuristics (see simulated annealing).
在开发蒙特卡罗方法之前,人们模拟测试了一个已经解决的确定性问题,统计抽样用于估计模拟中的不确定性。蒙特卡罗模拟将这种方法反转,使用概率元启发式方法解决确定性问题(参见模拟退火)。
An early variant of the Monte Carlo method was devised to solve the Buffon's needle problem, in which 模板:Pi can be estimated by dropping needles on a floor made of parallel equidistant strips. In the 1930s, Enrico Fermi first experimented with the Monte Carlo method while studying neutron diffusion, but he did not publish this work.模板:Sfn
An early variant of the Monte Carlo method was devised to solve the Buffon's needle problem, in which can be estimated by dropping needles on a floor made of parallel equidistant strips. In the 1930s, Enrico Fermi first experimented with the Monte Carlo method while studying neutron diffusion, but he did not publish this work.
蒙特卡罗方法的早期变种被设计来解决布丰投针问题,在布丰投针问题中,π可以通过将针落在由平行等距条组成的地板上来估计。20世纪30年代,恩里科·费米在研究中子扩散时首次尝试了蒙特卡罗方法,但他没有发表这项工作
In the late 1940s, Stanislaw Ulam invented the modern version of the Markov Chain Monte Carlo method while he was working on nuclear weapons projects at the Los Alamos National Laboratory. Immediately after Ulam's breakthrough, John von Neumann understood its importance. Von Neumann programmed the ENIAC computer to perform Monte Carlo calculations. In 1946, nuclear weapons physicists at Los Alamos were investigating neutron diffusion in fissionable material.模板:Sfn Despite having most of the necessary data, such as the average distance a neutron would travel in a substance before it collided with an atomic nucleus and how much energy the neutron was likely to give off following a collision, the Los Alamos physicists were unable to solve the problem using conventional, deterministic mathematical methods. Ulam proposed using random experiments. He recounts his inspiration as follows:
In the late 1940s, Stanislaw Ulam invented the modern version of the Markov Chain Monte Carlo method while he was working on nuclear weapons projects at the Los Alamos National Laboratory. Immediately after Ulam's breakthrough, John von Neumann understood its importance. Von Neumann programmed the ENIAC computer to perform Monte Carlo calculations. In 1946, nuclear weapons physicists at Los Alamos were investigating neutron diffusion in fissionable material. Despite having most of the necessary data, such as the average distance a neutron would travel in a substance before it collided with an atomic nucleus and how much energy the neutron was likely to give off following a collision, the Los Alamos physicists were unable to solve the problem using conventional, deterministic mathematical methods. Ulam proposed using random experiments. He recounts his inspiration as follows:
20世纪40年代末,斯坦尼斯拉夫·乌拉姆 Stanislaw Ulam在洛斯阿拉莫斯国家实验室研究核武器项目时,发明了现代版的马尔可夫链蒙特卡罗方法。在乌拉姆的突破之后,约翰·冯·诺伊曼立即意识到了它的重要性。冯·诺伊曼为ENIAC(人类第一台电子数字积分计算机)编写了程序来进行蒙特卡罗计算。1946年,洛斯阿拉莫斯的核武器物理学家正在研究中子在可裂变材料中的扩散。尽管拥有大部分必要的数据,例如中子在与原子核碰撞之前在物质中的平均运行距离,以及碰撞后中子可能释放出多少能量,但洛斯阿拉莫斯的物理学家们无法用传统的、确定性的数学方法解决这个问题。此时乌拉姆建议使用随机实验。他后来回忆当初灵感产生过程:
The first thoughts and attempts I made to practice [the Monte Carlo Method] were suggested by a question which occurred to me in 1946 as I was convalescing from an illness and playing solitaires. The question was what are the chances that a Canfield solitaire laid out with 52 cards will come out successfully? After spending a lot of time trying to estimate them by pure combinatorial calculations, I wondered whether a more practical method than "abstract thinking" might not be to lay it out say one hundred times and simply observe and count the number of successful plays. This was already possible to envisage with the beginning of the new era of fast computers, and I immediately thought of problems of neutron diffusion and other questions of mathematical physics, and more generally how to change processes described by certain differential equations into an equivalent form interpretable as a succession of random operations. Later [in 1946], I described the idea to John von Neumann, and we began to plan actual calculations.
我最初的想法和尝试蒙特卡洛法是在1946年,当时我正从疾病中康复,时常玩单人纸牌游戏。那时我会思考这样一个问题:一盘52张的加菲尔德纸牌成功出牌的几率有多大?在花了大量时间尝试通过纯粹的组合计算来估计它们之后,我想知道是否有一种比“抽象思维”更实际的方法,可能不是将它展开100次,然后简单地观察和计算成功的游戏数量。在快速计算机新时代开始时,这已经是可以想象的了,我立刻想到了中子扩散和其他数学物理的问题,以及更一般的情形—如何将由某些微分方程描述的过程转换成可解释为一系列随机操作的等价形式。后来(1946年),我向约翰·冯·诺伊曼描述了这个想法,然后我们开始计划实际的计算。
/* Styling for Template:Quote */ .templatequote { overflow: hidden; margin: 1em 0; padding: 0 40px; } .templatequote .templatequotecite {
line-height: 1.5em; /* @noflip */ text-align: left; /* @noflip */ padding-left: 1.6em; margin-top: 0;
}
Being secret, the work of von Neumann and Ulam required a code name.模板:Sfn A colleague of von Neumann and Ulam, Nicholas Metropolis, suggested using the name Monte Carlo, which refers to the Monte Carlo Casino in Monaco where Ulam's uncle would borrow money from relatives to gamble.模板:Sfn Using lists of "truly random" random numbers was extremely slow, but von Neumann developed a way to calculate pseudorandom numbers, using the middle-square method. Though this method has been criticized as crude, von Neumann was aware of this: he justified it as being faster than any other method at his disposal, and also noted that when it went awry it did so obviously, unlike methods that could be subtly incorrect.[11]
Being secret, the work of von Neumann and Ulam required a code name. A colleague of von Neumann and Ulam, Nicholas Metropolis, suggested using the name Monte Carlo, which refers to the Monte Carlo Casino in Monaco where Ulam's uncle would borrow money from relatives to gamble. Using lists of "truly random" random numbers was extremely slow, but von Neumann developed a way to calculate pseudorandom numbers, using the middle-square method. Though this method has been criticized as crude, von Neumann was aware of this: he justified it as being faster than any other method at his disposal, and also noted that when it went awry it did so obviously, unlike methods that could be subtly incorrect.
冯 · 诺依曼和乌拉姆的工作是秘密进行的,需要一个代号。冯 · 诺依曼和乌拉姆的一位同事,尼古拉斯·梅特罗波利斯建议使用蒙特卡洛这个名字,这个名字指的是摩纳哥的蒙特卡洛赌场,乌拉姆的叔叔会和亲戚借钱然后去那里赌博。使用“真正随机”的随机数列表是非常慢的,然而冯 · 诺依曼使用平方取中法开发了一种计算伪随机数生成器的方法。虽然许多人一直批评这种方法较为粗糙原始,但是冯 · 诺依曼也意识到这一点:他证明这种方法比任何其他方法都快,并指出当它出错时,人们可以轻易发现,不像其他方法产生的错误可能会不易察觉。
Monte Carlo methods were central to the simulations required for the Manhattan Project, though severely limited by the computational tools at the time. In the 1950s they were used at Los Alamos for early work relating to the development of the hydrogen bomb, and became popularized in the fields of physics, physical chemistry, and operations research. The Rand Corporation and the U.S. Air Force were two of the major organizations responsible for funding and disseminating information on Monte Carlo methods during this time, and they began to find a wide application in many different fields.
Monte Carlo methods were central to the simulations required for the Manhattan Project, though severely limited by the computational tools at the time. In the 1950s they were used at Los Alamos for early work relating to the development of the hydrogen bomb, and became popularized in the fields of physics, physical chemistry, and operations research. The Rand Corporation and the U.S. Air Force were two of the major organizations responsible for funding and disseminating information on Monte Carlo methods during this time, and they began to find a wide application in many different fields.
尽管受到当时的计算工具严重限制,蒙特卡洛方法依然是曼哈顿计划所需模拟的核心关键。20世纪50年代,它们在洛斯阿拉莫斯用于与氢弹开发有关的早期工作,并在物理学、物理化学和运筹学领域得到普及。兰德公司和美国空军是当时负责资助和传播蒙特卡罗方法信息的两个主要组织,从那时起他们开始在许多不同的领域广泛地应用这一方法。
The theory of more sophisticated mean field type particle Monte Carlo methods had certainly started by the mid-1960s, with the work of Henry P. McKean Jr. on Markov interpretations of a class of nonlinear parabolic partial differential equations arising in fluid mechanics.[12][13] We also quote an earlier pioneering article by Theodore E. Harris and Herman Kahn, published in 1951, using mean field genetic-type Monte Carlo methods for estimating particle transmission energies.[14] Mean field genetic type Monte Carlo methodologies are also used as heuristic natural search algorithms (a.k.a. metaheuristic) in evolutionary computing. The origins of these mean field computational techniques can be traced to 1950 and 1954 with the work of Alan Turing on genetic type mutation-selection learning machines[15] and the articles by Nils Aall Barricelli at the Institute for Advanced Study in Princeton, New Jersey.[16][17]
The theory of more sophisticated mean field type particle Monte Carlo methods had certainly started by the mid-1960s, with the work of Henry P. McKean Jr. on Markov interpretations of a class of nonlinear parabolic partial differential equations arising in fluid mechanics. We also quote an earlier pioneering article by Theodore E. Harris and Herman Kahn, published in 1951, using mean field genetic-type Monte Carlo methods for estimating particle transmission energies. Mean field genetic type Monte Carlo methodologies are also used as heuristic natural search algorithms (a.k.a. metaheuristic) in evolutionary computing. The origins of these mean field computational techniques can be traced to 1950 and 1954 with the work of Alan Turing on genetic type mutation-selection learning machines and the articles by Nils Aall Barricelli at the Institute for Advanced Study in Princeton, New Jersey.
更复杂的平均场型粒子蒙特卡罗方法的理论产生于20世纪60年代中期,最初来自于小亨利·麦基恩 Henry P. McKean Jr. 研究流体力学中出现的一类非线性抛物型偏微分方程的马尔可夫解释。西奥多·爱德华·哈里斯 Theodore E. Harris和赫曼·卡恩 Herman Kahn在1951年发表了一篇开创性文章,使用平均场遗传型蒙特卡罗方法来估计粒子传输能量。这一方法在演化计算中也被用作启发式自然搜索算法(又称元启发式)。这些平均场计算技术的起源可以追溯到1950年和1954年,当时艾伦·图灵 Alan Turing在基因类型突变-选择学习机器上的工作,以及来自新泽西州普林斯顿高等研究院的尼尔斯·阿尔·巴里里利 Nils Aall Barricelli的文章。
Quantum Monte Carlo, and more specifically diffusion Monte Carlo methods can also be interpreted as a mean field particle Monte Carlo approximation of Feynman–Kac path integrals.[18][19][20][21][22][23][24] The origins of Quantum Monte Carlo methods are often attributed to Enrico Fermi and Robert Richtmyer who developed in 1948 a mean field particle interpretation of neutron-chain reactions,[25] but the first heuristic-like and genetic type particle algorithm (a.k.a. Resampled or Reconfiguration Monte Carlo methods) for estimating ground state energies of quantum systems (in reduced matrix models) is due to Jack H. Hetherington in 1984[24] In molecular chemistry, the use of genetic heuristic-like particle methodologies (a.k.a. pruning and enrichment strategies) can be traced back to 1955 with the seminal work of Marshall N. Rosenbluth and Arianna W. Rosenbluth.[26]
量子蒙特卡罗方法,更具体地说,扩散蒙特卡罗方法也可以解释为费曼—卡茨路径积分的平均场粒子蒙特卡罗近似。量子蒙特卡罗方法的起源通常归功于恩里科·费米Enrico Fermi和罗伯特·里希特迈耶 Robert Richtmyer于1948年开发了中子链式反应的平均场粒子解释,但是用于估计量子系统的基态能量(在简化矩阵模型中)的第一个类启发式和遗传型粒子算法(也称为重取样或重构蒙特卡洛方法)则是由杰克·H·海瑟林顿在1984年提出。在分子化学中,使用遗传类启发式的粒子方法(又名删减和富集策略)可以追溯到1955年—马歇尔·罗森布鲁斯 Marshall Rosenbluth和阿里安娜·罗森布鲁斯Arianna Rosenbluth的开创性工作。
Kalos and Whitlock point out that such distinctions are not always easy to maintain. For example, the emission of radiation from atoms is a natural stochastic process. It can be simulated directly, or its average behavior can be described by stochastic equations that can themselves be solved using Monte Carlo methods. "Indeed, the same computer code can be viewed simultaneously as a 'natural simulation' or as a solution of the equations by natural sampling."
卡洛斯和惠特洛克指出,这种区别并不总是容易维持。例如,来自原子的辐射是一种自然的随机过程。它可以直接模拟,也可以用随机方程描述其平均行为,这些随机方程本身可以用蒙特卡罗方法求解。“实际上,同样的计算机代码可以同时被看作是‘自然模拟’或者通过自然抽样解方程。”
The use of Sequential Monte Carlo in advanced signal processing and Bayesian inference is more recent. It was in 1993, that Gordon et al., published in their seminal work[27] the first application of a Monte Carlo resampling algorithm in Bayesian statistical inference. The authors named their algorithm 'the bootstrap filter', and demonstrated that compared to other filtering methods, their bootstrap algorithm does not require any assumption about that state-space or the noise of the system. We also quote another pioneering article in this field of Genshiro Kitagawa on a related "Monte Carlo filter",[28] and the ones by Pierre Del Moral[29] and Himilcon Carvalho, Pierre Del Moral, André Monin and Gérard Salut[30] on particle filters published in the mid-1990s. Particle filters were also developed in signal processing in 1989–1992 by P. Del Moral, J. C. Noyer, G. Rigal, and G. Salut in the LAAS-CNRS in a series of restricted and classified research reports with STCAN (Service Technique des Constructions et Armes Navales), the IT company DIGILOG, and the LAAS-CNRS (the Laboratory for Analysis and Architecture of Systems) on radar/sonar and GPS signal processing problems.[31][32][33][34][35][36] These Sequential Monte Carlo methodologies can be interpreted as an acceptance-rejection sampler equipped with an interacting recycling mechanism.
在高级信号处理和贝叶斯推断中使用序列蒙特卡罗方法是最近才出现的。1993年,高登等人在他们的开创性工作中发表了蒙特卡罗重采样算法在贝叶斯推论统计学中的首次应用。作者将他们的算法命名为“自举过滤器” ,并证明了与其他过滤方法相比,他们的自举过滤算法不需要任何关于系统状态空间或噪声的假设。此外北川源四郎也进行了”蒙特卡洛过滤器”相关的开创性研究;在1990年代中期,皮埃尔·德尔·莫勒尔 Pierre Del Moral和希米尔康 · 卡瓦略 Himilcon Carvalho以及皮埃尔 · 德尔 · 莫勒尔、安德烈 · 莫宁 André Monin和杰拉德 · 萨鲁特 Gérard Salut发表了关于粒子过滤器的文章。1989-1992年间,在LAAS-CNRS (系统分析和体系结构实验室),皮埃尔·德尔·莫勒尔、J·C·诺亚 J. C. Noyer、G·里加尔 G. Rigal 和杰拉德 · 萨鲁特开发了粒子滤波器用于信号处理。他们与STCAN (海军建造和武装服务技术部)、IT公司DIGILOG共同完成了一系列关于雷达/声纳和GPS信号处理问题的限制性和机密性研究报告。这些序列蒙特卡罗方法可以解释为一个接受拒绝采样器配备了相互作用的回收机制。
Monte Carlo simulations are typically characterized by many unknown parameters, many of which are difficult to obtain experimentally. Monte Carlo simulation methods do not always require truly random numbers to be useful (although, for some applications such as primality testing, unpredictability is vital). Many of the most useful techniques use deterministic, pseudorandom sequences, making it easy to test and re-run simulations. The only quality usually necessary to make good simulations is for the pseudo-random sequence to appear "random enough" in a certain sense.
蒙特卡罗模拟的典型特征是有许多未知参数,其中许多参数很难通过实验获得。蒙特卡罗模拟方法并不总是要求真正的随机数是有用的(尽管对于一些应用程序,如质数测试,不可预测性是至关重要的)。许多最有用的技术使用确定性的伪随机序列,使测试和重新运行模拟变得很容易。伪随机序列在某种意义上表现地“足够随机”,这是进行良好模拟所必需的唯一品质。
From 1950 to 1996, all the publications on Sequential Monte Carlo methodologies, including the pruning and resample Monte Carlo methods introduced in computational physics and molecular chemistry, present natural and heuristic-like algorithms applied to different situations without a single proof of their consistency, nor a discussion on the bias of the estimates and on genealogical and ancestral tree based algorithms. The mathematical foundations and the first rigorous analysis of these particle algorithms were written by Pierre Del Moral in 1996.[29][37]
从1950年到1996年,所有关于顺序蒙特卡罗方法的出版物,包括计算物理和分子化学中引入的删减和重采样蒙特卡罗方法,目前应用于不同的情况的自然和类启发式算法,没有任何一致性证明,也没有讨论估计的偏差和基于谱系和遗传树的算法。皮埃尔 · 德尔 · 莫勒尔在1996年的写作中阐述了关于这些粒子算法的数学基础,并对其第一次进行了严格的分析。
What this means depends on the application, but typically they should pass a series of statistical tests. Testing that the numbers are uniformly distributed or follow another desired distribution when a large enough number of elements of the sequence are considered is one of the simplest and most common ones. Weak correlations between successive samples are also often desirable/necessary.
其中的含义一般取决于应用,但通常应该通过一系列统计测试。当考虑序列中足够多的元素时,检验这些数是均匀分布的,还是遵循另一个期望的分布是最简单常见的方法之一。连续样本之间的弱相关性通常也是可取的,或必要的。(和维基原文相比多出来的部分)
Branching type particle methodologies with varying population sizes were also developed in the end of the 1990s by Dan Crisan, Jessica Gaines and Terry Lyons,[38][39][40] and by Dan Crisan, Pierre Del Moral and Terry Lyons.[41] Further developments in this field were developed in 2000 by P. Del Moral, A. Guionnet and L. Miclo.[19][42][43]
20世纪90年代末,丹·克里桑 Dan Crisan、杰西卡·盖恩斯 Jessica Gaines和特里·利昂斯 Terry Lyons,以及丹·克里桑、皮埃尔·德尔·莫勒尔和特里·利昂斯也发展了具有不同种群大小的分支型粒子方法。2000年,皮埃尔·德尔·莫勒尔、爱丽丝·吉奥内 A. Guionnet和洛朗·米克洛 L. Miclo进一步发展了这一领域。
Sawilowsky lists the characteristics of a high-quality Monte Carlo simulation:
萨维罗斯基 Sawilowsky列出了高质量蒙特卡罗模拟的特点:(和维基原文相比多出来的部分)
Definitions
A Monte Carlo method simulation is defined as any method that utilizes sequences of random numbers to perform the simulation. Monte Carlo simulations are applied to many topics including quantum chromodynamics, cancer radiation therapy, traffic flow, stellar evolution and VLSI design. All these simulations require the use of random numbers and therefore pseudorandom number generators, which makes creating random-like numbers very important.
蒙特卡罗方法模拟被定义为任何利用随机数序列来执行模拟的方法。蒙特卡罗模拟应用于许多课题,包括量子色动力学,癌症放射治疗,交通流,恒星进化和超大规模集成电路设计。所有这些模拟都需要使用随机数,因此产生类随机数的伪随机数生成器非常重要。(和维基原文相比多出来的部分)
There is no consensus on how Monte Carlo should be defined. For example, Ripley[44] defines most probabilistic modeling as stochastic simulation, with Monte Carlo being reserved for Monte Carlo integration and Monte Carlo statistical tests. Sawilowsky[45] distinguishes between a simulation, a Monte Carlo method, and a Monte Carlo simulation: a simulation is a fictitious representation of reality, a Monte Carlo method is a technique that can be used to solve a mathematical or statistical problem, and a Monte Carlo simulation uses repeated sampling to obtain the statistical properties of some phenomenon (or behavior). Examples:
- Simulation: Drawing one pseudo-random uniform variable from the interval [0,1] can be used to simulate the tossing of a coin: If the value is less than or equal to 0.50 designate the outcome as heads, but if the value is greater than 0.50 designate the outcome as tails. This is a simulation, but not a Monte Carlo simulation.
- Monte Carlo method: Pouring out a box of coins on a table, and then computing the ratio of coins that land heads versus tails is a Monte Carlo method of determining the behavior of repeated coin tosses, but it is not a simulation.
- Monte Carlo simulation: Drawing ''a large number'' of pseudo-random uniform variables from the interval [0,1] at one time, or once at many different times, and assigning values less than or equal to 0.50 as heads and greater than 0.50 as tails, is a ''Monte Carlo simulation'' of the behavior of repeatedly tossing a coin.
对于如何定义蒙特卡洛还没有达成共识。例如,Ripley将大多数概率建模定义为随机模拟,蒙特卡罗保留用于蒙特卡罗积分和蒙特卡罗统计检验。Sawilowsky[54]区分了模拟、蒙特卡罗方法和蒙特卡罗模拟:蒙特卡罗方法是一种可以用来解决数学或统计问题的技术,蒙特卡罗模拟使用重复抽样来获得某些现象(或行为)的统计特性。例如:
A simple example of how a computer would perform a Monte Carlo simulation is the calculation of π. If a square enclosed a circle and a point were randomly chosen inside the square the point would either lie inside the circle or outside it. If the process were repeated many times, the ratio of the random points that lie inside the circle to the total number of random points in the square would approximate the ratio of the area of the circle to the area of the square. From this we can estimate pi, as shown in the Python code below utilizing a SciPy package to generate pseudorandom numbers with the MT19937 algorithm. Note that this method is a computationally inefficient way to numerically approximate π.
计算机进行蒙特卡罗模拟的一个简单实例是 π 的计算。如果一个正方形包含一个圆,一个点在正方形内被随机选择,那么这个点要么在圆内,要么在圆外。如果这个过程重复多次,圆内的随机点与正方形内随机点总数的比值将近似于圆的面积与正方形面积的比值。由此我们可以估算π,如下面的Python代码所示,利用 SciPy 包使用 MT19937算法生成伪随机数生成器。值得注意的是,这种从数值上近似得到π的方法计算效率低下。
“ syntaxhighlight lang = " python" ”
*Monte Carlo simulation: Drawing ''a large number'' of pseudo-random uniform variables from the interval [0,1] at one time, or once at many different times, and assigning values less than or equal to 0.50 as heads and greater than 0.50 as tails, is a ''Monte Carlo simulation'' of the behavior of repeatedly tossing a coin.
import scipy
输入接头
Kalos and Whitlock<ref name="Kalos">{{harvnb|Kalos|Whitlock|2008}}</ref> point out that such distinctions are not always easy to maintain. For example, the emission of radiation from atoms is a natural stochastic process. It can be simulated directly, or its average behavior can be described by stochastic equations that can themselves be solved using Monte Carlo methods. "Indeed, the same computer code can be viewed simultaneously as a 'natural simulation' or as a solution of the equations by natural sampling."
N = 100000
100000
x_array = scipy.random.rand(N)
X _ array = scipy.random.rand (n)
===Monte Carlo and random numbers===
y_array = scipy.random.rand(N)
Y _ array = scipy.random.rand (n)
generate N pseudorandom independent x and y-values on interval [0,1)
在区间[0,1]上生成 n 个与伪随机无关的 x 和 y 值
The main idea behind this method is that the results are computed based on repeated random sampling and statistical analysis. The Monte Carlo simulation is, in fact, random experimentations, in the case that, the results of these experiments are not well known.
N_qtr_circle = sum(x_array ** 2 + y_array ** 2 < 1)
N _ qtr _ circle = sum (x _ array * * 2 + y _ array * * 2 < 1)
Monte Carlo simulations are typically characterized by many unknown parameters, many of which are difficult to obtain experimentally.<ref name="usaus">{{cite journal|last1 = Shojaeefard|first1 = MH| last2 = Khalkhali|first2 = A| last3 =Yarmohammadisatri|first3 = Sadegh|title = An efficient sensitivity analysis method for modified geometry of Macpherson suspension based on Pearson Correlation Coefficient|journal = Vehicle System Dynamics|volume = 55|issue = 6|pages = 827–852|doi = 10.1080/00423114.2017.1283046|year = 2017|bibcode = 2017VSD....55..827S|s2cid = 114260173}}</ref> Monte Carlo simulation methods do not always require [[Random number generation#"True" random numbers vs. pseudo-random numbers|truly random number]]s to be useful (although, for some applications such as [[primality testing]], unpredictability is vital).<ref>{{harvnb|Davenport|1992}}</ref> Many of the most useful techniques use deterministic, [[pseudorandom number generator|pseudorandom]] sequences, making it easy to test and re-run simulations. The only quality usually necessary to make good [[simulation]]s is for the pseudo-random sequence to appear "random enough" in a certain sense.
Number of pts within the quarter circle x^2 + y^2 < 1 centered at the origin with radius r=1.
以原点为中心,半径 r = 1的四分之一圆 x ^ 2 + y ^ 2 < 1内的点数。
True area of quarter circle is pi/4 and has N_qtr_circle points within it.
四分之一圆的真实面积是 π/4,其中有 n _ qtr _ 圆点。
What this means depends on the application, but typically they should pass a series of statistical tests. Testing that the numbers are [[Uniform distribution (continuous)|uniformly distributed]] or follow another desired distribution when a large enough number of elements of the sequence are considered is one of the simplest and most common ones. Weak correlations between successive samples are also often desirable/necessary.
True area of the square is 1 and has N points within it, hence we approximate pi with
平方的真实面积是1,并且有 n 个点在其中,因此我们用
pi_approx = 4 * float(N_qtr_circle) / N # Typical values: 3.13756, 3.15156
Pi _ approx = 4 * float (n _ qtr _ circle)/n # 典型值: 3.13756,3.15156
Sawilowsky lists the characteristics of a high-quality Monte Carlo simulation:<ref name=Sawilowsky/>
</syntaxhighlight >
- the (pseudo-random) number generator has certain characteristics (e.g. a long "period" before the sequence repeats)
- the (pseudo-random) number generator produces values that pass tests for randomness
- there are enough samples to ensure accurate results
There are ways of using probabilities that are definitely not Monte Carlo simulations – for example, deterministic modeling using single-point estimates. Each uncertain variable within a model is assigned a "best guess" estimate. Scenarios (such as best, worst, or most likely case) for each input variable are chosen and the results recorded.
使用概率的方法肯定不是蒙特卡洛模拟——例如,使用单点估计的确定性建模。模型中的每个不确定变量都被赋予一个“最佳猜测”估计。为每个输入变量选择场景(如最佳、最差或最可能的情况)并记录结果。
- the proper sampling technique is used
- the algorithm used is valid for what is being modeled
By contrast, Monte Carlo simulations sample from a probability distribution for each variable to produce hundreds or thousands of possible outcomes. The results are analyzed to get probabilities of different outcomes occurring. For example, a comparison of a spreadsheet cost construction model run using traditional "what if" scenarios, and then running the comparison again with Monte Carlo simulation and triangular probability distributions shows that the Monte Carlo analysis has a narrower range than the "what if" analysis. This is because the "what if" analysis gives equal weight to all scenarios (see quantifying uncertainty in corporate finance), while the Monte Carlo method hardly samples in the very low probability regions. The samples in such regions are called "rare events".
相比之下,蒙特卡罗模拟从概率分布中抽取每个变量的样本,产生数百或数千个可能的结果。对结果进行分析,得到不同结果发生的概率。例如,对使用传统”如果”情景运行的电子表格成本构造模型进行比较,然后再与蒙特卡罗模拟和三角概率分布进行比较,结果表明蒙特卡罗分析的范围比”如果”分析的范围窄。这是因为“如果”分析对所有情景给予了同等的权重(见量化公司融资的不确定性) ,而蒙特卡罗方法基金组织几乎不在非常低的概率区域抽样。这些地区的样品被称为“稀有事件”。
- it simulates the phenomenon in question.
Pseudo-random number sampling algorithms are used to transform uniformly distributed pseudo-random numbers into numbers that are distributed according to a given probability distribution.
Monte Carlo methods are especially useful for simulating phenomena with significant uncertainty in inputs and systems with many coupled degrees of freedom. Areas of application include:
蒙特卡罗方法尤其适用于模拟输入和多自由度耦合系统中具有明显不确定性的现象。申请范围包括:
Low-discrepancy sequences are often used instead of random sampling from a space as they ensure even coverage and normally have a faster order of convergence than Monte Carlo simulations using random or pseudorandom sequences. Methods based on their use are called quasi-Monte Carlo methods.
In an effort to assess the impact of random number quality on Monte Carlo simulation outcomes, astrophysical researchers tested cryptographically-secure pseudorandom numbers generated via Intel's RDRAND instruction set, as compared to those derived from algorithms, like the Mersenne Twister, in Monte Carlo simulations of radio flares from brown dwarfs. RDRAND is the closest pseudorandom number generator to a true random number generator. No statistically significant difference was found between models generated with typical pseudorandom number generators and RDRAND for trials consisting of the generation of 107 random numbers.[46]
Monte Carlo methods are very important in computational physics, physical chemistry, and related applied fields, and have diverse applications from complicated quantum chromodynamics calculations to designing heat shields and aerodynamic forms as well as in modeling radiation transport for radiation dosimetry calculations. In statistical physics Monte Carlo molecular modeling is an alternative to computational molecular dynamics, and Monte Carlo methods are used to compute statistical field theories of simple particle and polymer systems. Quantum Monte Carlo methods solve the many-body problem for quantum systems. In experimental particle physics, Monte Carlo methods are used for designing detectors, understanding their behavior and comparing experimental data to theory. In astrophysics, they are used in such diverse manners as to model both galaxy evolution and microwave radiation transmission through a rough planetary surface. Monte Carlo methods are also used in the ensemble models that form the basis of modern weather forecasting.
蒙特卡罗方法在计算物理学、物理化学和相关应用领域中非常重要,并且有各种各样的应用,从复杂的量子色动力学计算到设计热屏和空气动力学形式,以及辐射剂量计算的辐射传输模型。在统计物理学中,蒙特卡罗分子模拟是计算分子动力学的一种替代方法,而蒙特卡罗方法被用来计算简单粒子和聚合物体系的统计场理论。量子蒙特卡罗法方法解决了量子系统的多体问题。在实验粒子物理学中,蒙特卡罗方法被用来设计探测器,了解它们的行为,并将实验数据与理论进行比较。在天体物理学中,它们以各种不同的方式被用来模拟星系演化和微波辐射通过粗糙行星表面的传输。蒙特卡罗方法也用于构成现代天气预报基础的集合模型中。
Mersenne_twister (MT19937) in Python (a Monte Carlo method simulation)
A Monte Carlo method simulation is defined as any method that utilizes sequences of random numbers to perform the simulation. Monte Carlo simulations are applied to many topics including quantum chromodynamics, cancer radiation therapy, traffic flow, stellar evolution and VLSI design. All these simulations require the use of random numbers and therefore pseudorandom number generators, which makes creating random-like numbers very important.
Monte Carlo methods are widely used in engineering for sensitivity analysis and quantitative probabilistic analysis in process design. The need arises from the interactive, co-linear and non-linear behavior of typical process simulations. For example,
蒙特卡罗方法被广泛应用于工程设计中的敏感度分析和工艺设计中的定量概率分析。这种需求来源于典型过程模拟的交互性、共线性和非线性行为。比如说,
A simple example of how a computer would perform a Monte Carlo simulation is the calculation of π. If a square enclosed a circle and a point were randomly chosen inside the square the point would either lie inside the circle or outside it. If the process were repeated many times, the ratio of the random points that lie inside the circle to the total number of random points in the square would approximate the ratio of the area of the circle to the area of the square. From this we can estimate pi, as shown in the Python code below utilizing a SciPy package to generate pseudorandom numbers with the MT19937 algorithm. Note that this method is a computationally inefficient way to numerically approximate π.
import scipy
N = 100000
x_array = scipy.random.rand(N)
y_array = scipy.random.rand(N)
# generate N pseudorandom independent x and y-values on interval [0,1)
N_qtr_circle = sum(x_array ** 2 + y_array ** 2 < 1)
# Number of pts within the quarter circle x^2 + y^2 < 1 centered at the origin with radius r=1.
# True area of quarter circle is pi/4 and has N_qtr_circle points within it.
# True area of the square is 1 and has N points within it, hence we approximate pi with
pi_approx = 4 * float(N_qtr_circle) / N # Typical values: 3.13756, 3.15156
The Intergovernmental Panel on Climate Change relies on Monte Carlo methods in probability density function analysis of radiative forcing.
政府间气候变化专门委员会基于蒙特卡罗方法对概率密度函数辐射效应进行分析。
Monte Carlo simulation versus "what if" scenarios
There are ways of using probabilities that are definitely not Monte Carlo simulations – for example, deterministic modeling using single-point estimates. Each uncertain variable within a model is assigned a "best guess" estimate. Scenarios (such as best, worst, or most likely case) for each input variable are chosen and the results recorded.[47]
By contrast, Monte Carlo simulations sample from a probability distribution for each variable to produce hundreds or thousands of possible outcomes. The results are analyzed to get probabilities of different outcomes occurring.[48] For example, a comparison of a spreadsheet cost construction model run using traditional "what if" scenarios, and then running the comparison again with Monte Carlo simulation and triangular probability distributions shows that the Monte Carlo analysis has a narrower range than the "what if" analysis.模板:Examples This is because the "what if" analysis gives equal weight to all scenarios (see quantifying uncertainty in corporate finance), while the Monte Carlo method hardly samples in the very low probability regions. The samples in such regions are called "rare events".
Monte Carlo methods are used in various fields of computational biology, for example for Bayesian inference in phylogeny, or for studying biological systems such as genomes, proteins, or membranes.
蒙特卡罗方法被用于计算生物学的各个领域,例如在系统发育学中的贝叶斯推断,或者用于研究生物系统,例如基因组、蛋白质或膜。
The systems can be studied in the coarse-grained or ab initio frameworks depending on the desired accuracy.
该系统可以在粗粒度或从头开始框架中研究,这取决于所需的准确性。
Applications
Computer simulations allow us to monitor the local environment of a particular molecule to see if some chemical reaction is happening for instance. In cases where it is not feasible to conduct a physical experiment, thought experiments can be conducted (for instance: breaking bonds, introducing impurities at specific sites, changing the local/global structure, or introducing external fields).
计算机模拟使我们能够监测特定分子的局部环境,看看是否正在发生某种化学反应,例如。在无法进行物理实验的情况下,可以进行思维实验(例如: 打破键,在特定位置引入杂质,改变局部/全球结构,或引入外部场)。
Monte Carlo methods are especially useful for simulating phenomena with significant uncertainty in inputs and systems with many coupled degrees of freedom. Areas of application include:
Physical sciences
Path tracing, occasionally referred to as Monte Carlo ray tracing, renders a 3D scene by randomly tracing samples of possible light paths. Repeated sampling of any given pixel will eventually cause the average of the samples to converge on the correct solution of the rendering equation, making it one of the most physically accurate 3D graphics rendering methods in existence.
路径追踪,偶尔被称为蒙特卡罗光线追踪,通过随机追踪可能光路的样本来呈现一个三维场景。对任何给定像素的重复采样最终将导致样本的平均值收敛到渲染方程的正确解,使其成为现存物理上最精确的3 d 图形渲染方法之一。
Monte Carlo methods are very important in computational physics, physical chemistry, and related applied fields, and have diverse applications from complicated quantum chromodynamics calculations to designing heat shields and aerodynamic forms as well as in modeling radiation transport for radiation dosimetry calculations.[49][50][51] In statistical physics Monte Carlo molecular modeling is an alternative to computational molecular dynamics, and Monte Carlo methods are used to compute statistical field theories of simple particle and polymer systems.[26][52] Quantum Monte Carlo methods solve the many-body problem for quantum systems.[8][9][18] In radiation materials science, the binary collision approximation for simulating ion implantation is usually based on a Monte Carlo approach to select the next colliding atom.[53] In experimental particle physics, Monte Carlo methods are used for designing detectors, understanding their behavior and comparing experimental data to theory. In astrophysics, they are used in such diverse manners as to model both galaxy evolution[54] and microwave radiation transmission through a rough planetary surface.[55] Monte Carlo methods are also used in the ensemble models that form the basis of modern weather forecasting.
The standards for Monte Carlo experiments in statistics were set by Sawilowsky. In applied statistics, Monte Carlo methods may be used for at least four purposes:
蒙特卡罗方法的统计标准是由 Sawilowsky 制定的。在应用统计学中,蒙特卡罗方法至少可用于四种目的:
To compare competing statistics for small samples under realistic data conditions. Although type I error and power properties of statistics can be calculated for data drawn from classical theoretical distributions (e.g., normal curve, Cauchy distribution) for asymptotic conditions (i. e, infinite sample size and infinitesimally small treatment effect), real data often do not have such distributions.
比较在现实数据条件下小样本的竞争统计。虽然 i 型误差和统计的幂次特性可以计算从经典的理论分布(例如,正态曲线,柯西分布)的数据的渐近条件(即,无限大的样本量和无限小的处理效果) ,实际数据往往没有这样的分布。
Engineering
To provide implementations of hypothesis tests that are more efficient than exact tests such as permutation tests (which are often impossible to compute) while being more accurate than critical values for asymptotic distributions.
提供比精确检验更有效的假设检验的实现,例如排列检验(通常无法计算) ,同时比渐近分布的临界值更精确。
Monte Carlo methods are widely used in engineering for sensitivity analysis and quantitative probabilistic analysis in process design. The need arises from the interactive, co-linear and non-linear behavior of typical process simulations. For example,
To provide a random sample from the posterior distribution in Bayesian inference. This sample then approximates and summarizes all the essential features of the posterior.
提供一份来自后验概率贝叶斯推断的随机样本。这个样本然后估计和总结所有的基本特征后。
- In microelectronics engineering, Monte Carlo methods are applied to analyze correlated and uncorrelated variations in analog and digital integrated circuits.
To provide efficient random estimates of the Hessian matrix of the negative log-likelihood function that may be averaged to form an estimate of the Fisher information matrix.
提供负对数似然函数的 Hessian 矩阵的有效的随机估计,这些估计的平均值可以形成费雪资讯矩阵的估计。
- In geostatistics and geometallurgy, Monte Carlo methods underpin the design of mineral processing flowsheets and contribute to quantitative risk analysis.[56]
- In wind energy yield analysis, the predicted energy output of a wind farm during its lifetime is calculated giving different levels of uncertainty (P90, P50, etc.)
Monte Carlo methods are also a compromise between approximate randomization and permutation tests. An approximate randomization test is based on a specified subset of all permutations (which entails potentially enormous housekeeping of which permutations have been considered). The Monte Carlo approach is based on a specified number of randomly drawn permutations (exchanging a minor loss in precision if a permutation is drawn twice—or more frequently—for the efficiency of not having to track which permutations have already been selected).
蒙特卡罗方法也是近似随机化和置换检验的折衷。近似随机化测试是基于所有排列的特定子集(这需要潜在的庞大的内务管理,其中排列已被考虑)。蒙特卡罗方法是基于一定数量的随机排列(如果排列被抽取两次或更频繁,精度会有轻微的损失,因为不必追踪哪些排列已经被选择)。
- In fluid dynamics, in particular rarefied gas dynamics, where the Boltzmann equation is solved for finite Knudsen number fluid flows using the direct simulation Monte Carlo[59] method in combination with highly efficient computational algorithms.[60]
- In autonomous robotics, Monte Carlo localization can determine the position of a robot. It is often applied to stochastic filters such as the Kalman filter or particle filter that forms the heart of the SLAM (simultaneous localization and mapping) algorithm.
- In telecommunications, when planning a wireless network, design must be proved to work for a wide variety of scenarios that depend mainly on the number of users, their locations and the services they want to use. Monte Carlo methods are typically used to generate these users and their states. The network performance is then evaluated and, if results are not satisfactory, the network design goes through an optimization process.
- In reliability engineering, Monte Carlo simulation is used to compute system-level response given the component-level response. For example, for a transportation network subject to an earthquake event, Monte Carlo simulation can be used to assess the k-terminal reliability of the network given the failure probability of its components, e.g. bridges, roadways, etc.[61][62][63]
- In signal processing and Bayesian inference, particle filters and sequential Monte Carlo techniques are a class of mean field particle methods for sampling and computing the posterior distribution of a signal process given some noisy and partial observations using interacting empirical measures.
Monte Carlo methods have been developed into a technique called Monte-Carlo tree search that is useful for searching for the best move in a game. Possible moves are organized in a search tree and many random simulations are used to estimate the long-term potential of each move. A black box simulator represents the opponent's moves.
蒙特卡罗方法已经发展成为一种叫做蒙特卡洛树搜索的技术,它可以用来搜索游戏中的最佳移动。可能的移动被组织在一个搜索树和许多随机模拟被用来估计每个移动的长期潜力。一个黑盒模拟器代表对手的动作。
Climate change and radiative forcing
The Monte Carlo tree search (MCTS) method has four steps:
蒙特卡罗树搜索(MCTS)方法有四个步骤:
Starting at root node of the tree, select optimal child nodes until a leaf node is reached.
从树的根节点开始,选择最佳的子节点,直到达到叶节点。
The Intergovernmental Panel on Climate Change relies on Monte Carlo methods in probability density function analysis of radiative forcing.
Expand the leaf node and choose one of its children.
展开叶节点并选择其中一个子节点。
Play a simulated game starting with that node.
以该节点开始玩一个模拟游戏。
/* Styling for Template:Quote */ .templatequote { overflow: hidden; margin: 1em 0; padding: 0 40px; } .templatequote .templatequotecite {
line-height: 1.5em; /* @noflip */ text-align: left; /* @noflip */ padding-left: 1.6em; margin-top: 0;
}
Use the results of that simulated game to update the node and its ancestors.
使用模拟游戏的结果来更新节点及其祖先。
Computational biology
The net effect, over the course of many simulated games, is that the value of a node representing a move will go up or down, hopefully corresponding to whether or not that node represents a good move.
在许多模拟游戏过程中,净效应是代表移动的一个节点的值将上升或下降,希望与该节点是否代表一个好的移动相对应。
Monte Carlo methods are used in various fields of computational biology, for example for Bayesian inference in phylogeny, or for studying biological systems such as genomes, proteins,[64] or membranes.[65]
Monte Carlo Tree Search has been used successfully to play games such as Go, Tantrix, Battleship, Havannah, and Arimaa.
蒙特卡洛树搜索已成功地用于游戏,如围棋,Tantrix,战舰,Havannah,和 Arimaa。
The systems can be studied in the coarse-grained or ab initio frameworks depending on the desired accuracy.
Computer simulations allow us to monitor the local environment of a particular molecule to see if some chemical reaction is happening for instance. In cases where it is not feasible to conduct a physical experiment, thought experiments can be conducted (for instance: breaking bonds, introducing impurities at specific sites, changing the local/global structure, or introducing external fields).
Computer graphics
Path tracing, occasionally referred to as Monte Carlo ray tracing, renders a 3D scene by randomly tracing samples of possible light paths. Repeated sampling of any given pixel will eventually cause the average of the samples to converge on the correct solution of the rendering equation, making it one of the most physically accurate 3D graphics rendering methods in existence.
Monte Carlo methods are also efficient in solving coupled integral differential equations of radiation fields and energy transport, and thus these methods have been used in global illumination computations that produce photo-realistic images of virtual 3D models, with applications in video games, architecture, design, computer generated films, and cinematic special effects.
蒙特卡罗方法在解决辐射场和能量传输的耦合积分微分方程方面也很有效,因此这些方法已经被用于全局光源计算,产生虚拟3 d 模型的照片般逼真的图像,应用于视频游戏、建筑、设计、计算机生成的电影和电影特效。
Applied statistics
The standards for Monte Carlo experiments in statistics were set by Sawilowsky.[66] In applied statistics, Monte Carlo methods may be used for at least four purposes:
The US Coast Guard utilizes Monte Carlo methods within its computer modeling software SAROPS in order to calculate the probable locations of vessels during search and rescue operations. Each simulation can generate as many as ten thousand data points that are randomly distributed based upon provided variables. Search patterns are then generated based upon extrapolations of these data in order to optimize the probability of containment (POC) and the probability of detection (POD), which together will equal an overall probability of success (POS). Ultimately this serves as a practical application of probability distribution in order to provide the swiftest and most expedient method of rescue, saving both lives and resources.
美国海岸警卫队在其计算机建模软件 SAROPS 中使用蒙特卡罗方法,以便在搜索和救援行动中计算可能的船只位置。每个模拟可以生成多达一万个数据点,这些数据点是根据提供的变量随机分布的。然后根据这些数据的推断生成搜索模式,以优化包容概率(POC)和检测概率(POD) ,这两者合起来等于总体成功概率(POS)。最终,这作为概率分布的一个实际应用,以提供最迅速和最便捷的救援方法,拯救生命和资源。
- To compare competing statistics for small samples under realistic data conditions. Although type I error and power properties of statistics can be calculated for data drawn from classical theoretical distributions (e.g., normal curve, Cauchy distribution) for asymptotic conditions (i. e, infinite sample size and infinitesimally small treatment effect), real data often do not have such distributions.[67]
- To provide implementations of hypothesis tests that are more efficient than exact tests such as permutation tests (which are often impossible to compute) while being more accurate than critical values for asymptotic distributions.
- To provide a random sample from the posterior distribution in Bayesian inference. This sample then approximates and summarizes all the essential features of the posterior.
- To provide efficient random estimates of the Hessian matrix of the negative log-likelihood function that may be averaged to form an estimate of the Fisher information matrix.[68][69]
Monte Carlo simulation is commonly used to evaluate the risk and uncertainty that would affect the outcome of different decision options. Monte Carlo simulation allows the business risk analyst to incorporate the total effects of uncertainty in variables like sales volume, commodity and labour prices, interest and exchange rates, as well as the effect of distinct risk events like the cancellation of a contract or the change of a tax law.
蒙特卡罗模拟通常用于评估影响不同决策方案结果的风险和不确定性。蒙特卡洛模拟允许商业风险分析师在销售量、商品和劳动力价格、利率和汇率等变量中考虑不确定性的总体影响,以及不同风险事件的影响,如合同的取消或税法的改变。
Monte Carlo methods are also a compromise between approximate randomization and permutation tests. An approximate randomization test is based on a specified subset of all permutations (which entails potentially enormous housekeeping of which permutations have been considered). The Monte Carlo approach is based on a specified number of randomly drawn permutations (exchanging a minor loss in precision if a permutation is drawn twice—or more frequently—for the efficiency of not having to track which permutations have already been selected).
Monte Carlo methods in finance are often used to evaluate investments in projects at a business unit or corporate level, or other financial valuations. They can be used to model project schedules, where simulations aggregate estimates for worst-case, best-case, and most likely durations for each task to determine outcomes for the overall project.[1] Monte Carlo methods are also used in option pricing, default risk analysis. Additionally, they can be used to estimate the financial impact of medical interventions.
金融领域的蒙特卡罗方法通常用于评估一个业务单位或公司层面的项目投资,或其他金融估值。它们可以用于对项目进度表进行建模,模拟对每个任务的最坏情况、最好情况和最可能的持续时间进行聚合估计,以确定整个项目的结果。蒙特卡罗方法也用于期权定价,违约风险分析 https://risk.octigo.pl/。此外,它们还可以用来评估医疗干预措施的财务影响。
A Monte Carlo approach was used for evaluating the potential value of a proposed program to help female petitioners in Wisconsin be successful in their applications for harassment and domestic abuse restraining orders. It was proposed to help women succeed in their petitions by providing them with greater advocacy thereby potentially reducing the risk of rape and physical assault. However, there were many variables in play that could not be estimated perfectly, including the effectiveness of restraining orders, the success rate of petitioners both with and without advocacy, and many others. The study ran trials that varied these variables to come up with an overall estimate of the success level of the proposed program as a whole.
蒙特卡洛方法被用来评估一个拟议的方案的潜在价值,以帮助威斯康星州的女性请愿者成功地申请骚扰和家庭虐待限制令。提议帮助妇女成功地提出请愿,向她们提供更多的宣传,从而有可能减少强奸和人身攻击的风险。然而,还有许多变量无法完全估计,包括限制令的有效性,上访者的成功率,无论有没有主张,以及许多其他因素。这项研究通过改变这些变量进行了试验,得出了对整个计划成功程度的总体评估。
Artificial intelligence for games
Monte Carlo methods have been developed into a technique called Monte-Carlo tree search that is useful for searching for the best move in a game. Possible moves are organized in a search tree and many random simulations are used to estimate the long-term potential of each move. A black box simulator represents the opponent's moves.[70]
In general, the Monte Carlo methods are used in mathematics to solve various problems by generating suitable random numbers (see also Random number generation) and observing that fraction of the numbers that obeys some property or properties. The method is useful for obtaining numerical solutions to problems too complicated to solve analytically. The most common application of the Monte Carlo method is Monte Carlo integration.
一般来说,蒙特卡罗方法在数学中通过产生合适的随机数(也见随机数产生)和观察符合某些性质的数字分数来解决各种问题。这种方法对于求解解析求解过于复杂的问题的数值解是有用的。蒙特卡罗方法最常用的应用是蒙地卡罗积分。
The Monte Carlo tree search (MCTS) method has four steps:[71]
- Starting at root node of the tree, select optimal child nodes until a leaf node is reached.
- Expand the leaf node and choose one of its children.
- Play a simulated game starting with that node.
Monte-Carlo integration works by comparing random points with the value of the function
蒙特卡罗积分是通过比较随机点和函数值来工作的
- Use the results of that simulated game to update the node and its ancestors.
Errors reduce by a factor of [math]\displaystyle{ \scriptstyle 1/\sqrt{N} }[/math]
错误减少一个因素 < math > scriptstyle 1/sqrt { n } </math >
The net effect, over the course of many simulated games, is that the value of a node representing a move will go up or down, hopefully corresponding to whether or not that node represents a good move.
Deterministic numerical integration algorithms work well in a small number of dimensions, but encounter two problems when the functions have many variables. First, the number of function evaluations needed increases rapidly with the number of dimensions. For example, if 10 evaluations provide adequate accuracy in one dimension, then 10100 points are needed for 100 dimensions—far too many to be computed. This is called the curse of dimensionality. Second, the boundary of a multidimensional region may be very complicated, so it may not be feasible to reduce the problem to an iterated integral. 100 dimensions is by no means unusual, since in many physical problems, a "dimension" is equivalent to a degree of freedom.
确定性数值积分算法在少数维上运行良好,但在函数具有多个变量时会遇到两个问题。首先,随着维数的增加,需要进行的功能评估的数量迅速增加。例如,如果10个评估在一个维度上提供了足够的精确度,那么100个维度需要10个 < sup > 100 点,这太多了以至于无法计算。这就是所谓的维数灾难。其次,多维区域的边界可能非常复杂,因此将问题简化为迭代积分可能是不可行的。100维绝对不是不寻常的,因为在许多物理问题中,一个“维度”等同于一个自由度。
Monte Carlo Tree Search has been used successfully to play games such as Go,[72] Tantrix,[73] Battleship,[74] Havannah,[75] and Arimaa.[76]
Monte Carlo methods provide a way out of this exponential increase in computation time. As long as the function in question is reasonably well-behaved, it can be estimated by randomly selecting points in 100-dimensional space, and taking some kind of average of the function values at these points. By the central limit theorem, this method displays [math]\displaystyle{ \scriptstyle 1/\sqrt{N} }[/math] convergence—i.e., quadrupling the number of sampled points halves the error, regardless of the number of dimensions. or the VEGAS algorithm.
蒙特卡罗方法提供了一种方法来摆脱这种指数增长的计算时间。只要所涉及的函数具有合理的性质,就可以在100维空间中随机选取一些点,并在这些点上取某种函数值的平均值来估计。通过中心极限定理,这个方法显示 < math > scriptstyle 1/sqrt { n } </math > 收敛,即,不管维数多少,将采样点的数目翻两番,误差减半。或者拉斯维加斯算法。
A similar approach, the quasi-Monte Carlo method, uses low-discrepancy sequences. These sequences "fill" the area better and sample the most important points more frequently, so quasi-Monte Carlo methods can often converge on the integral more quickly.
一个类似的方法,拟蒙特卡罗方法,使用低差异序列。这些序列能更好地“填充”区域,更频繁地采样最重要的点,因此拟蒙特卡罗方法往往能更快地收敛于积分。
Design and visuals
Another class of methods for sampling points in a volume is to simulate random walks over it (Markov chain Monte Carlo). Such methods include the Metropolis–Hastings algorithm, Gibbs sampling, Wang and Landau algorithm, and interacting type MCMC methodologies such as the sequential Monte Carlo samplers.
另一类方法是模拟体积上的随机游动(马尔科夫蒙特卡洛)。这些方法包括 Metropolis-Hastings 算法、 Gibbs 抽样、 Wang 和 Landau 算法以及交互式 MCMC 方法,如序贯蒙特卡罗抽样。
Monte Carlo methods are also efficient in solving coupled integral differential equations of radiation fields and energy transport, and thus these methods have been used in global illumination computations that produce photo-realistic images of virtual 3D models, with applications in video games, architecture, design, computer generated films, and cinematic special effects.[77]
Search and rescue
The US Coast Guard utilizes Monte Carlo methods within its computer modeling software SAROPS in order to calculate the probable locations of vessels during search and rescue operations. Each simulation can generate as many as ten thousand data points that are randomly distributed based upon provided variables.[78] Search patterns are then generated based upon extrapolations of these data in order to optimize the probability of containment (POC) and the probability of detection (POD), which together will equal an overall probability of success (POS). Ultimately this serves as a practical application of probability distribution in order to provide the swiftest and most expedient method of rescue, saving both lives and resources.[79]
Another powerful and very popular application for random numbers in numerical simulation is in numerical optimization. The problem is to minimize (or maximize) functions of some vector that often has many dimensions. Many problems can be phrased in this way: for example, a computer chess program could be seen as trying to find the set of, say, 10 moves that produces the best evaluation function at the end. In the traveling salesman problem the goal is to minimize distance traveled. There are also applications to engineering design, such as multidisciplinary design optimization. It has been applied with quasi-one-dimensional models to solve particle dynamics problems by efficiently exploring large configuration space. Reference is a comprehensive review of many issues related to simulation and optimization.
另一个强大的和非常流行的应用随机数在数值模拟是在数值优化。问题在于如何最小化(或最大化)某些向量的函数,这些向量通常具有多个维度。许多问题可以这样表述: 例如,一个计算机国际象棋程序可以被视为试图找到一组,比如说,10步棋,最终产生最好的评价函数。在旅行商问题中,目标是使旅行距离最小。在工程设计中也有一些应用,如多学科设计优化。它已被应用于准一维模型,以解决粒子动力学问题,有效地探索大型位形空间。参考文献是对许多与模拟和优化有关的问题的全面回顾。
Finance and business
The traveling salesman problem is what is called a conventional optimization problem. That is, all the facts (distances between each destination point) needed to determine the optimal path to follow are known with certainty and the goal is to run through the possible travel choices to come up with the one with the lowest total distance. However, let's assume that instead of wanting to minimize the total distance traveled to visit each desired destination, we wanted to minimize the total time needed to reach each destination. This goes beyond conventional optimization since travel time is inherently uncertain (traffic jams, time of day, etc.). As a result, to determine our optimal path we would want to use simulation - optimization to first understand the range of potential times it could take to go from one point to another (represented by a probability distribution in this case rather than a specific distance) and then optimize our travel decisions to identify the best path to follow taking that uncertainty into account.
旅行推销员问题被称为传统的最佳化问题问题。也就是说,确定最佳路径所需的所有事实(每个目的地之间的距离)都是确定无疑的,目标是通过可能的旅行选择得出总距离最小的路径。然而,让我们假设,我们不想最小化访问每个想要的目的地所需的总距离,而是想最小化到达每个目的地所需的总时间。这超越了传统的优化,因为旅行时间是固有的不确定性(交通堵塞,一天的时间,等)。因此,为了确定我们的最佳路径,我们需要使用模拟优化来首先了解从一个点到另一个点可能需要的时间范围(在这个例子中用概率分布代表,而不是特定的距离) ,然后优化我们的旅行决策,以确定最佳路径遵循考虑到这种不确定性。
Monte Carlo simulation is commonly used to evaluate the risk and uncertainty that would affect the outcome of different decision options. Monte Carlo simulation allows the business risk analyst to incorporate the total effects of uncertainty in variables like sales volume, commodity and labour prices, interest and exchange rates, as well as the effect of distinct risk events like the cancellation of a contract or the change of a tax law.
Probabilistic formulation of inverse problems leads to the definition of a probability distribution in the model space. This probability distribution combines prior information with new information obtained by measuring some observable parameters (data).
反问题的概率公式导致了模型空间中概率分布的定义。该概率分布将先前的信息与通过测量一些可观测的参数(数据)获得的新信息结合起来。
Monte Carlo methods in finance are often used to evaluate investments in projects at a business unit or corporate level, or other financial valuations. They can be used to model project schedules, where simulations aggregate estimates for worst-case, best-case, and most likely durations for each task to determine outcomes for the overall project.[2] Monte Carlo methods are also used in option pricing, default risk analysis.[80][81][82] Additionally, they can be used to estimate the financial impact of medical interventions.[83]
As, in the general case, the theory linking data with model parameters is nonlinear, the posterior probability in the model space may not be easy to describe (it may be multimodal, some moments may not be defined, etc.).
因为,在一般情况下,连接数据和模型参数的理论是非线性的,模型空间中的后验概率可能不容易描述(它可能是多模态的,一些矩可能没有定义,等等。).
Law
When analyzing an inverse problem, obtaining a maximum likelihood model is usually not sufficient, as we normally also wish to have information on the resolution power of the data. In the general case we may have many model parameters, and an inspection of the marginal probability densities of interest may be impractical, or even useless. But it is possible to pseudorandomly generate a large collection of models according to the posterior probability distribution and to analyze and display the models in such a way that information on the relative likelihoods of model properties is conveyed to the spectator. This can be accomplished by means of an efficient Monte Carlo method, even in cases where no explicit formula for the a priori distribution is available.
当分析一个反问题时,获得一个最大似然模型通常是不够的,因为我们通常也希望有关于数据的分辨率的信息。在一般情况下,我们可能有许多模型参数,检查的边际概率密度的兴趣可能是不切实际的,甚至无用的。但是,根据《后验概率可以伪随机生成大量的模型集合,并以这样一种方式分析和显示模型,模型属性的相对可能性信息被传达给观众,这是可能的。这可以通过一个有效的蒙特卡罗方法安全管理系统来实现,即使在没有黎曼显式公式安全管理先验概率的情况下。
A Monte Carlo approach was used for evaluating the potential value of a proposed program to help female petitioners in Wisconsin be successful in their applications for harassment and domestic abuse restraining orders. It was proposed to help women succeed in their petitions by providing them with greater advocacy thereby potentially reducing the risk of rape and physical assault. However, there were many variables in play that could not be estimated perfectly, including the effectiveness of restraining orders, the success rate of petitioners both with and without advocacy, and many others. The study ran trials that varied these variables to come up with an overall estimate of the success level of the proposed program as a whole.[84]
The best-known importance sampling method, the Metropolis algorithm, can be generalized, and this gives a method that allows analysis of (possibly highly nonlinear) inverse problems with complex a priori information and data with an arbitrary noise distribution.
最著名的重要性抽样方法,Metropolis–Hastings 演算法,可以推广,这提供了一种方法,允许分析(可能是高度非线性)与复杂的先验信息和数据与任意噪声分布的反问题。
Use in mathematics
In general, the Monte Carlo methods are used in mathematics to solve various problems by generating suitable random numbers (see also Random number generation) and observing that fraction of the numbers that obeys some property or properties. The method is useful for obtaining numerical solutions to problems too complicated to solve analytically. The most common application of the Monte Carlo method is Monte Carlo integration.
Popular exposition of the Monte Carlo Method was conducted by McCracken. Method's general philosophy was discussed by Elishakoff and Grüne-Yanoff and Weirich.
由 McCracken 主持的蒙特卡罗方法博览会的普及展览。方法的一般哲学由 Elishakoff、 Grüne-Yanoff 和 weurich 讨论。
Integration
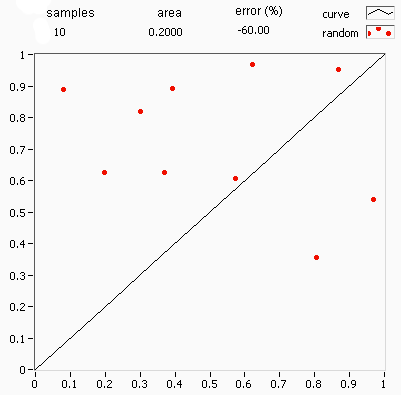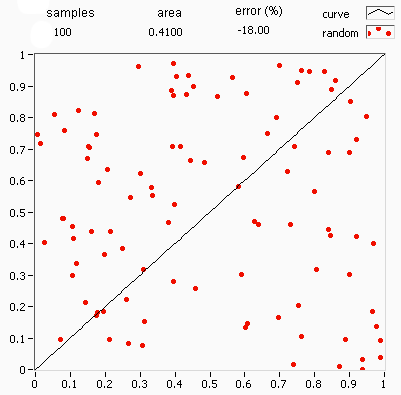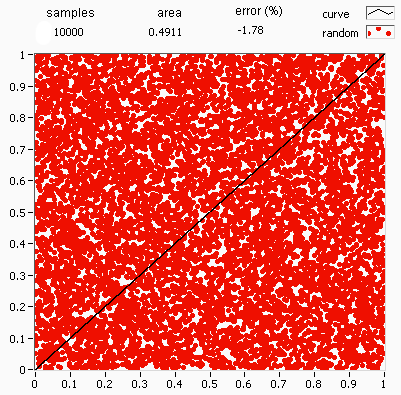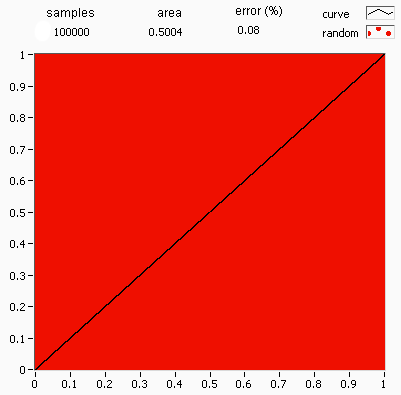
.png)
{kind=link}
{kind=link}
.png){kind=link}
Deterministic numerical integration algorithms work well in a small number of dimensions, but encounter two problems when the functions have many variables. First, the number of function evaluations needed increases rapidly with the number of dimensions. For example, if 10 evaluations provide adequate accuracy in one dimension, then 10100 points are needed for 100 dimensions—far too many to be computed. This is called the curse of dimensionality. Second, the boundary of a multidimensional region may be very complicated, so it may not be feasible to reduce the problem to an iterated integral.[85] 100 dimensions is by no means unusual, since in many physical problems, a "dimension" is equivalent to a degree of freedom.
Monte Carlo methods provide a way out of this exponential increase in computation time. As long as the function in question is reasonably well-behaved, it can be estimated by randomly selecting points in 100-dimensional space, and taking some kind of average of the function values at these points. By the central limit theorem, this method displays [math]\displaystyle{ \scriptstyle 1/\sqrt{N} }[/math] convergence—i.e., quadrupling the number of sampled points halves the error, regardless of the number of dimensions.[85]
A refinement of this method, known as importance sampling in statistics, involves sampling the points randomly, but more frequently where the integrand is large. To do this precisely one would have to already know the integral, but one can approximate the integral by an integral of a similar function or use adaptive routines such as stratified sampling, recursive stratified sampling, adaptive umbrella sampling[86][87] or the VEGAS algorithm.
A similar approach, the quasi-Monte Carlo method, uses low-discrepancy sequences. These sequences "fill" the area better and sample the most important points more frequently, so quasi-Monte Carlo methods can often converge on the integral more quickly.
Another class of methods for sampling points in a volume is to simulate random walks over it (Markov chain Monte Carlo). Such methods include the Metropolis–Hastings algorithm, Gibbs sampling, Wang and Landau algorithm, and interacting type MCMC methodologies such as the sequential Monte Carlo samplers.[88]
Simulation and optimization
Another powerful and very popular application for random numbers in numerical simulation is in numerical optimization. The problem is to minimize (or maximize) functions of some vector that often has many dimensions. Many problems can be phrased in this way: for example, a computer chess program could be seen as trying to find the set of, say, 10 moves that produces the best evaluation function at the end. In the traveling salesman problem the goal is to minimize distance traveled. There are also applications to engineering design, such as multidisciplinary design optimization. It has been applied with quasi-one-dimensional models to solve particle dynamics problems by efficiently exploring large configuration space. Reference[89] is a comprehensive review of many issues related to simulation and optimization.
The traveling salesman problem is what is called a conventional optimization problem. That is, all the facts (distances between each destination point) needed to determine the optimal path to follow are known with certainty and the goal is to run through the possible travel choices to come up with the one with the lowest total distance. However, let's assume that instead of wanting to minimize the total distance traveled to visit each desired destination, we wanted to minimize the total time needed to reach each destination. This goes beyond conventional optimization since travel time is inherently uncertain (traffic jams, time of day, etc.). As a result, to determine our optimal path we would want to use simulation - optimization to first understand the range of potential times it could take to go from one point to another (represented by a probability distribution in this case rather than a specific distance) and then optimize our travel decisions to identify the best path to follow taking that uncertainty into account.
Inverse problems
Probabilistic formulation of inverse problems leads to the definition of a probability distribution in the model space. This probability distribution combines prior information with new information obtained by measuring some observable parameters (data).
As, in the general case, the theory linking data with model parameters is nonlinear, the posterior probability in the model space may not be easy to describe (it may be multimodal, some moments may not be defined, etc.).
When analyzing an inverse problem, obtaining a maximum likelihood model is usually not sufficient, as we normally also wish to have information on the resolution power of the data. In the general case we may have many model parameters, and an inspection of the marginal probability densities of interest may be impractical, or even useless. But it is possible to pseudorandomly generate a large collection of models according to the posterior probability distribution and to analyze and display the models in such a way that information on the relative likelihoods of model properties is conveyed to the spectator. This can be accomplished by means of an efficient Monte Carlo method, even in cases where no explicit formula for the a priori distribution is available.
The best-known importance sampling method, the Metropolis algorithm, can be generalized, and this gives a method that allows analysis of (possibly highly nonlinear) inverse problems with complex a priori information and data with an arbitrary noise distribution.[90][91]
Philosophy
Popular exposition of the Monte Carlo Method was conducted by McCracken[92]. Method's general philosophy was discussed by Elishakoff[93] and Grüne-Yanoff and Weirich[94].
See also
References
Citations
Sources
======================= =============================-->
Category:Numerical analysis
类别: 数值分析
Category:Statistical mechanics
类别: 统计力学
Category:Computational physics
类别: 计算物理学
Category:Sampling techniques
类别: 抽样技术
Category:Statistical approximations
类别: 统计近似值
Category:Stochastic simulation
类别: 随机模拟
Category:Randomized algorithms
类别: 随机算法
Category:Risk analysis methodologies
类别: 风险分析方法
This page was moved from wikipedia:en:Monte Carlo method. Its edit history can be viewed at 蒙特卡洛模拟/edithistory
- 有模板循环的页面
- 有脚本错误的页面
- 引用模板后大小超过限制的页面
- Pages containing cite templates with deprecated parameters
- Harv and Sfn no-target errors
- Articles with short description
- All articles with unsourced statements
- Articles with unsourced statements from November 2019
- Articles with invalid date parameter in template
- 保护状态与保护标志不符的页面
- Articles with hatnote templates targeting a nonexistent page
- 待整理页面