因果推断引擎
跳到导航
跳到搜索
定义
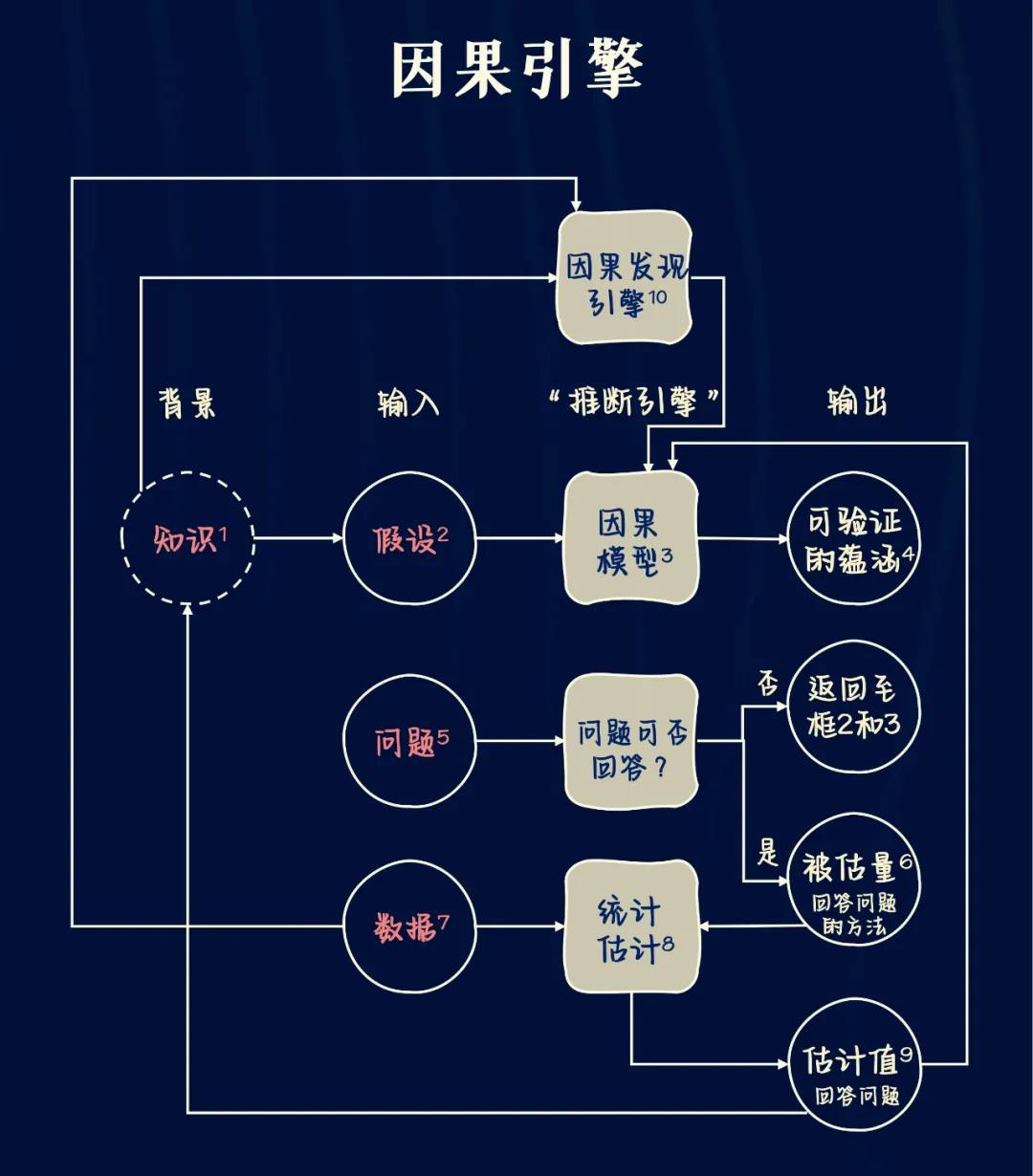
因果发现引擎是一种从观测数据中发现出可能的因果模型的机器,它接受两种输入——假设和数据,产生的输出为一个或一簇因果模型。下图展示了“因果引擎”的概貌。

因果推断引擎
流程介绍
因果推断引擎是一种问题处理机器,它接收三种不同的输入——假设、问题和数据,并能够产生三种输出。
第一种输出是“是/否”判断,用于判定在现有的因果模型下,假设我们拥有完美的、无限的数据,那么给定的问题在理论上是否有解。如果答案为“是”,则接下来推断引擎会生成一个被估量。这是一个数学公式,可以被理解为一种能从任何假设数据中生成答案的方法,只要这些数据是可获取的。最后,在推断引擎接收到数据输入后,它将用上述方法生成一个问题答案的实际估计值,并给出对该估计值的不确定性大小的统计估计。这种不确定性反映了样本数据集的代表性以及可能存在的测量误差或数据缺失。
名词解释
通过结合以下案例来解释推理引擎的各部分含义:
假设乔在服用药物 A 一个月后死亡,那么我们关注的问题就是这种药物A是否导致它的死亡。为了回答这个问题,我们需要想象这样一种情况:加入乔在即将服药时改变了主义,他现在会活着吗?
- 知识:知识指的是推理主体过去的经验。知识周围的虚线框表示它仍然隐藏在推理主体的思想中,尚未在模型中正式表达。
- 假设:假设是研究者在现有的知识的基础上认为有必要明确表达出来的陈述。
- 因果模型:表示可以反应变量因果关系的形式载体,有多种表现形式,包括因果图、结构方程、逻辑等。
- 可验证的蕴涵:以因果模型的路径来表示的变量之间的听从模式通常会导向数据某种显而易见的模式或者相关关系。这些模式可被用于测试模型,因此被称为“可验证的蕴含(testable implications)”。即 服用药物A和 乔死亡事件DEATH之间没有连接路径翻译成统计学语言,为A和 DEATH之间相互独立。若实际数据与之相互抵触,则修改模型。
- 问题:向因果引擎提交的问题即希望获得解决的科学问题。
- 被估量:被估量(estimand)是从数据中估算出来的统计量。具有概率公式的表现形式,实际上可以让我们根据所掌握的数据类型回答因果问题。
- 若 A 和 DEATH 依赖第三变量 U 且无法收集 U 的值,则问题就无法得到解答。
- 需要完善模型,可以通过输入新的知识或者简化假设(可能存在失败的风险)
- 数据:数据是填充被估量的原料,而其本身不具备表述因果关系的能力。被估量可以将这些统计量转化成表达式。
- 统计估计:得到的估计值只是近似值。可以通过诸如机器学习领域提供的先进技术来应对近似结果的不确定性。
- 估计值:最后,如果模型正确且数据充分,则获得待解决的因果问题的答案。